
PDEM测评报告深度解读:百目魔君大模型领跑宠物医疗AI赛道
宠物诊断大语言模型主观客观测评法PDEM作为全球首个宠物诊断大语言模型专业测评体系,旨在通过标准化框架评估AI模型在动物医疗领域的真实诊断能力,于近日公布其最新测评报告。
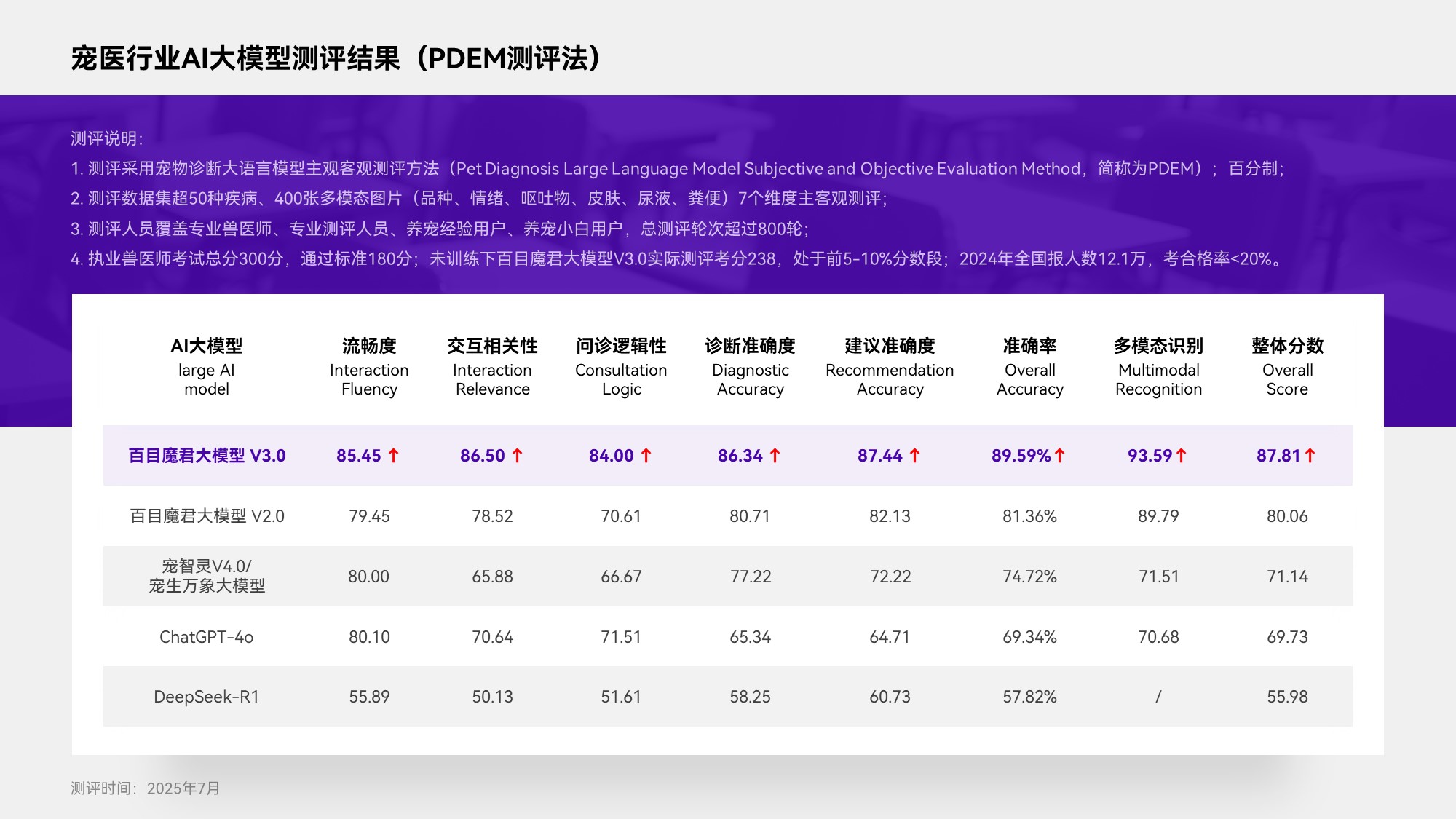
此次测评采用百分制量化评分,数据集覆盖50余种犬猫常见及罕见疾病、400张多模态图片,涵盖品种、情绪、呕吐物、皮肤、尿液、粪便等7个维度,测评团队由专业兽医师、AI测评专家、资深养宠用户及新手宠主组成,历经800余轮次交叉验证,确保评估结果的科学性与行业参考价值。
一、测评对象及得分排名:宠医垂域模型与通用模型的分野
本次PDEM测评范围涵盖宠医垂直领域专业与通用型的大模型,包括百目魔君大模型V3.0与V2.0、宠智灵V4.0大模型(宠生万象)、ChatGPT-4o及DeepSeek-R1。结果显示,宠医健康助手汪喵灵灵自研的百目魔君大模型V3.0以绝对优势夺冠,以综合评分87.81排行第一;其V2.0版本以约10%的诊断能力差距紧随其后。宠智灵大模型V4.0作为宠医垂直领域的另一代表以71.14分排行第三,其结构化诊断模式在特定场景中展现一定的稳定性。而ChatGPT-4o与DeepSeek-R1作为通用大模型凭借自然语言处理优势和交互能力分别位列第四、五位。
二、能力解读:从问诊逻辑看技术路线差异
1.百目魔君V3.0:循证医学的AI实践
该模型的核心竞争力在于对临床路径的深度复刻。在PDEM测评案例中,面对"狗狗屁股鼓包"的主诉,其通过“软硬度”“排便变化”等5轮追问,精准锁定会阴疝诊断,与真人兽医结论完全一致,可见百目魔君大模型的诊断准确性和专业度。这种多轮交互能力源于96K超长上下文推理技术,使其能像资深兽医般动态排除干扰项。同时其通过检索增强生成技术将模型幻觉率降至近乎为零,可靠性远超行业平均水平。
汪喵灵灵披露团队在2024年底完成了互联网信息服务算法备案,成为行业内首个通过国家大模型备案的宠物医疗大模型,这代表着百目魔君大模型在合规、数据安全和技术标准上都达到了国家相关法律法规要求。
2.宠智灵V4.0/宠生万象:结构化诊断的双刃剑
该模型交互层面设计完善,通过预设问题路径能确保覆盖常见答案,但也牺牲了开放性发问的交互体验。测评过程显示,宠智灵大模型将用户未作答的问题视为默认肯定,可能导致“假阳性”判断;需警惕的是,其用药推荐机制未过滤人用药,显示出宠智灵大模型的训练数据在合规性校准方面有待完善。
3.通用大模型:泛化有余,专业不足
通用大模型ChatGPT-4o和DeepSeek-R1,在理解复杂上下文和互动自然性方面表现出色,但在宠物医疗专业性上存在明显短板。在面对宠物医疗问题时,难以精准地捕捉关键症状,只能全面地提供可能存在的病因,无法给出准确的诊断判断。这表明通用大模型虽然在自然语言处理和交互方面具有优势,但在特定的宠物医疗领域,仍需经过进一步的专业优化和训练。
三、宠物医疗AI大模型的发展方向:精准、专业、安全、自然缺一不可
PDEM测评清晰地指明了宠物医疗AI大模型未来的竞争核心与发展路径,将聚焦于四大关键能力的协同进化:
● 诊断精准度:通过高质量的模型训练与多模态信息融合,不断增强模型在复杂病情识别和推理能力,持续提供模型判断的专业性和可用性。
● 专业知识:构建动态更新的兽医智脑,深度融入兽医学体系,建立结构化知识库,并确保通过联网及新技术应用等方式实现知识的实时更新与前沿性。
● 安全可靠:筑牢不可逾越的底线,遵循法规确保诊断准确性及用药安全,杜绝人药兽用的推荐;彻底消除模型幻觉,保障所有信息输出真实可靠、有据可循。
● 交互体验:具备强大的上下文理解与记忆能力,支持自然、灵活的多轮深度对话,并能提供清晰易懂的解释。
最新PDEM测评报告显示,百目魔君大模型凭借卓越的动物诊断能力领跑宠物AI赛道,为养宠家庭及宠业上下游厂商提供高效智诊方案。同时,宠智灵、DeepSeek-R1等模型亦展现出差异化价值,满足多元场景需求。随着技术演进,宠物医疗AI大模型将深度赋能智能诊断、远程医疗及健康管理,驱动行业向数智时代全面转型。


